
Tightening design-to-code alignment with token system overhaul
I modernized an 18-month-old token system and added an AI guardrail that nearly eliminated token hallucinations.
The problem
Eighteen months after their introduction, the system the tokens were communicating had changed a bit. Our brand and styles was more defined than it had been when I was first defining the variables. Overtime, one-off updates had been done to make updates, and improve discoverability and usability.
Lastly, company strategy had shifted to include more 0-1 work. This meant more non-components were being used in early-stage work. Teams were also using more AI tools and we wanted the tokens to be a considered part of that process.

Key decisions
Resolve all our issues identified with our current token set:
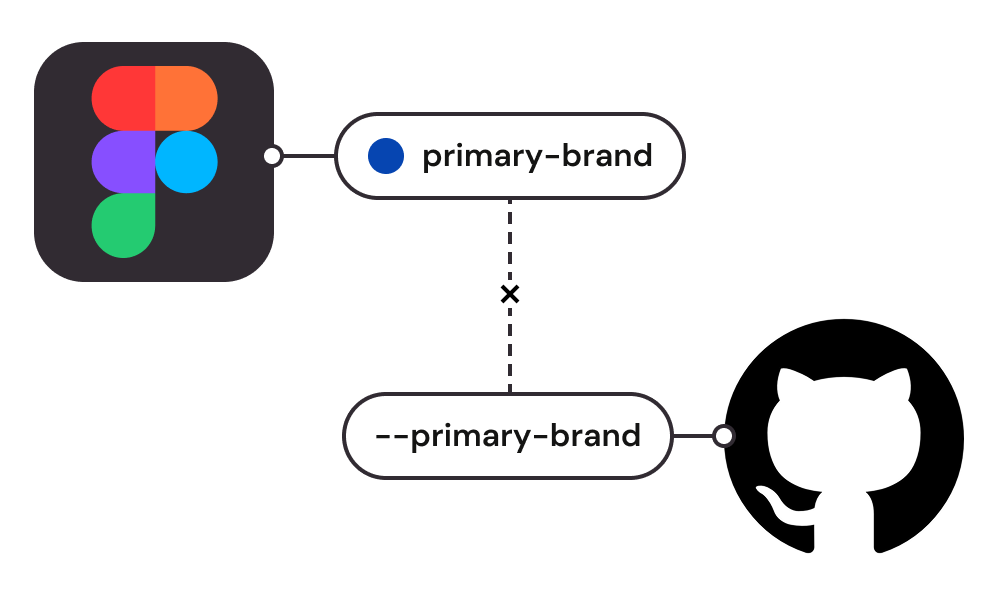
Reconcile naming conflicts
Formally adopt name changes that were made for improved discoverability and/or usability
Align Figma variable set to design tokens in code
Lastly, Figma’s variable feature had improved since we first launched. Consequently, our export process was able to be streamlined.
My role
I worked with 3 different engineers throughout this process.
The engineer that originally helped launch tokens was a thought partner and provided overall guidance.
I worked with another engineer to actually do the token reconciliation. Additionally, he manually mapped some of the outlier and hallucinated tokens in the codebase.
The third engineer partner was a member of our AI tools team and helped iterate and test the skills that reduced our hallucinated tokens.

Impact
We were able to remove all unofficial tokens from the codebase.
We were able to dramatically simplify the management of design tokens and move oversight to design.
We saw a 108% improvement to hallucinated tokens after adding safeguards to Claude Code.

Impact of v1 token set
Our first version of tokens was introduced in 2024. Over the following 18 months, the token set successfully improved the consistency of design work across the Academia experience. We tightened up our brand expression and reduced unnecessary tokens. We also saw significant improvements in our designer <> developer hand-off process. This was evidenced by a reduction of changes happening during design QA.
Issues identified
Limited resources are allocated to our design system. To date, we have only prioritized changes absolutely necessary.
In the time since first launch, our brand, organization, and engineering process have seen lots of change.
Our brand was more defined than it had been when tokens were first introduced. These decisions have evolved our UI and typography styles.
After 18 months of regular use, I had made changes to our variables to support designer ease-of-use. This included tweaks to token names for better discoverability and adjustments to token values to better align with design decisions.
Company strategy shifted to include more 0-1 work. This meant more non-components were being used in early-stage work.
Design tokens were increasingly valuable in an engineering process that had shifted to include more AI tools. Unfortunately, we are also dealing with a surge of invented variables. Using Claude Code’s documentation feature, we wanted to introduce guidance and rules to reduce hallucinations.
From audit to launch
Auditing the current state of tokens
First, my engineering partner pulled all the existing tokens from our code base. We compared them to the current state of tokens in our Figma library file to understand what has changed, what is new, and what tokens are conflicting.
Some conflicts are purposeful, like:

Our naming change from ‘corner radius’ to ‘border radius’ to align with CSS language.

We needed more variation in our beige choices as background colors. Our beige palette has become our go-to supporting color.

The interactive-based names for tokens were originally meant to be component-specific. After their use cases expanded, renaming them allowed for better discovery in Figma. Leading with the token type (‘background’, ‘stroke’) ensures that similar tokens are grouped in the Figma palette window.
Some conflicts deserve to be walked back:

At some point I had updated the names of the stroke color options to be more precise. However, this wasn’t a change worth keeping and I reverted back to the original -light, -medium, and -dark convention.
The last category of changes were value only.
These were to be expected as a natural state of iteration.
Updating the source tokens
After I reconciled all conflicts, I updated the tokens in the Figma library.
Some changes needed additional mapping details. For a small subset of tokens, we needed to map old tokens to the new naming convention so as not to break what was already in production.
This step was also an opportunity to identify and correct hallucinated tokens created by AI coding tools. All hallucinated tokens were re-mapped to their proper counterpart.
Setting up safeguards
Hallucinated tokens were cropping up in our codebase as the use of AI tools increased. In an effort to curb this, I worked with another engineer to introduce Claude Skill documentation to reduce AI’s output of invented variables. The skill guides Claude Code to discover and use existing DS components instead of building custom UI and to use CSS custom properties instead of hardcoded values.
Early signal shows an +108% improvement. With no Skill initiated, we see a 45% success rate. With the Skill, we’ve seen that increase to 94%.
Publish & QA
Finally, the new tokens were published, and we solicited engineering and design support to QA the entire experience to identify any mistakes.

LISWP before token update
LISWP after the token update
Process changes and ownership
Moving forward, design will be responsible for the end-to-end token system. I will oversee the introduction of new variables, align our various token depositories, and be responsible for pushing regular updates to production.
This change removed the engineering bottleneck that had previously plagued design system work.